The recent raising of Layer 2 solutions, especially Zero-Knowledge based, require coming back to Data Availability concepts, especially for the Ethereum ecosystem where the full archive node size has reached almost 15TB. In this article, we will explore the concept of data availability in Web3, and its importance and delve into several pioneering projects in this field: Celestia, EigenDA, Fuel, and Syntropy. For more details about layer 2 smart contract audit, contact the Mundus Security team today!
Check out our website and please join our community!
Data Availability in Web3
The data availability layer is a crucial component of the modular blockchain stack, ensuring that transaction-related data is accessible to all nodes on the blockchain network. It is a system that stores and provides consensus on the availability of blockchain data. This layer is essential for nodes to independently verify transactions and compute the blockchain’s state without trusting one another.
Data availability in blockchains refers to the ability of nodes to download the data contained within all blocks propagated through a peer-to-peer network. This is achieved through a process known as block verification, where block producers take transactions from the mempool, produce a new block with those transactions, and broadcast the new block to the P2P network to be added to the chain. Then, the validating nodes download transactions from the newly proposed block, re-execute the transactions to confirm compliance with consensus rules and add the block to the head of the chain once the network deems the block is valid.
However, the need for data availability presents challenges such as reducing throughput and limiting the number of entities that can run node infrastructure due to the requirement for nodes to download and verify data. This is where the data availability layer comes in, solving these challenges.
For example, Ethereum Full Archive Node is 15TB now
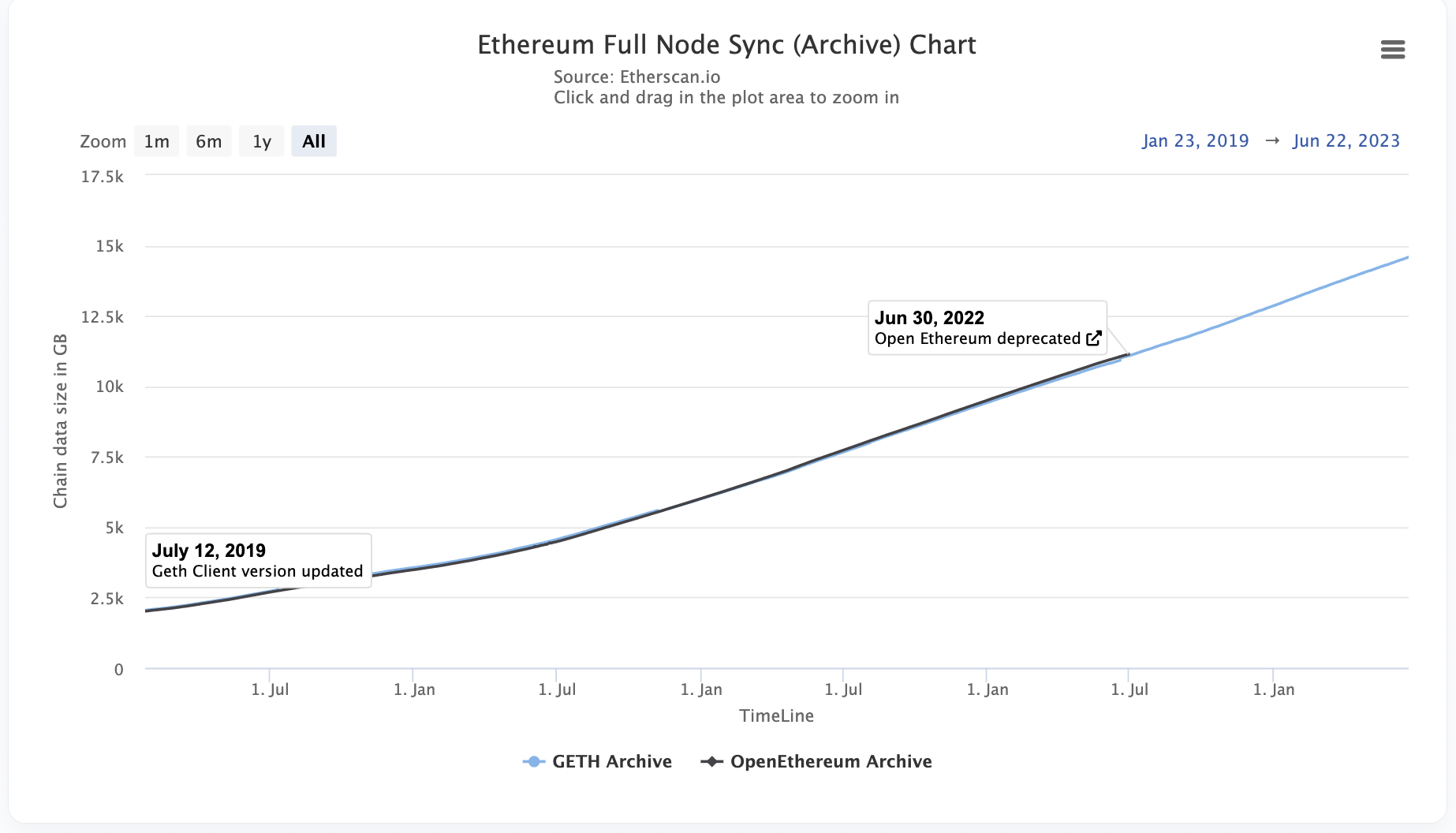
And Sync Node is trying not to exceed 1TB, but based on the current dynamic, it will exceed 1TB again in 3 months.
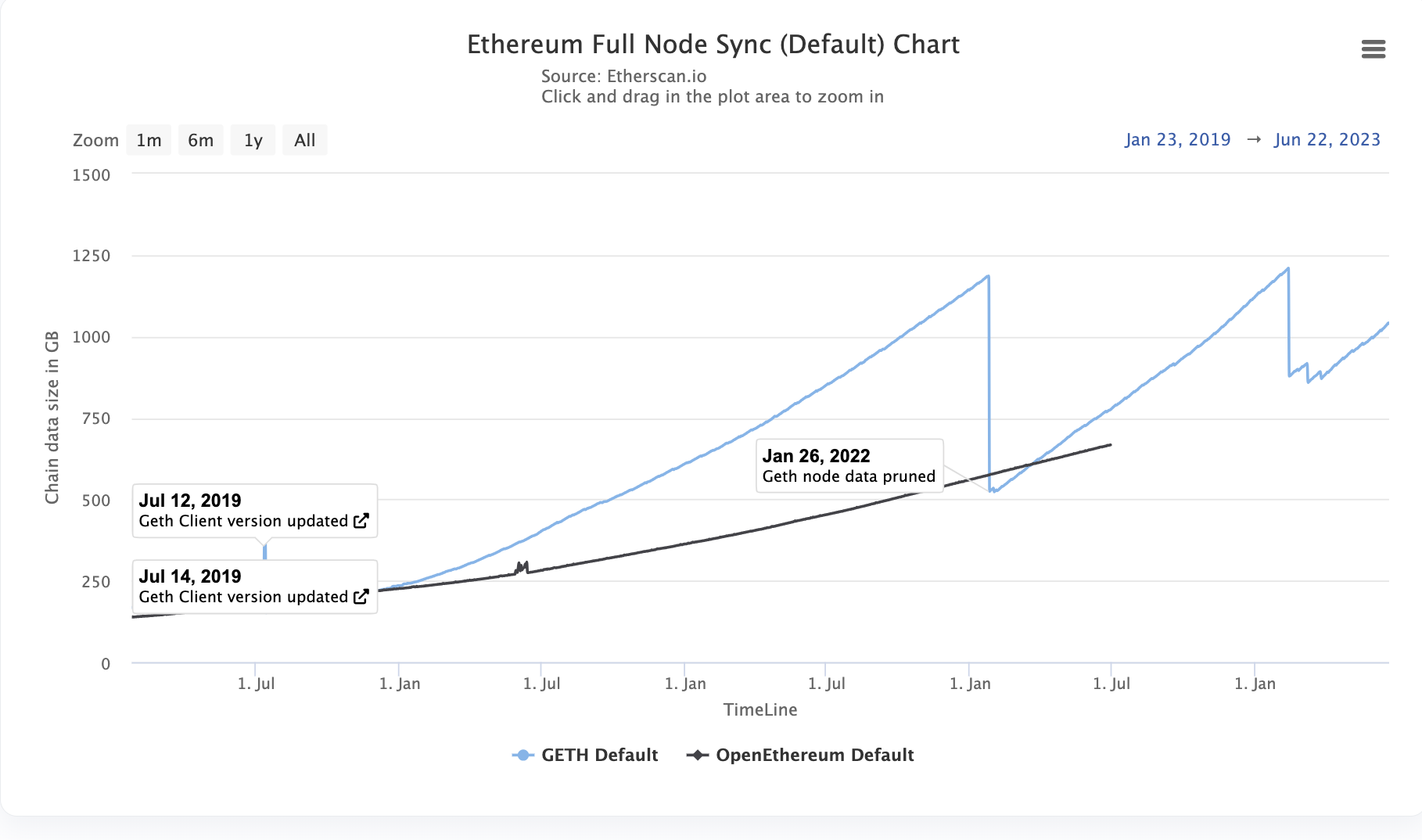
There are two types of data availability layers: On-chain data availability layer and Off-chain data availability layer:
- The on-chain data availability layer is the standard approach among many blockchains, in which data is stored on-chain by the nodes that execute transactions. While this ensures high data availability, it limits decentralization and scalability.
- On the other hand, the off-chain data availability layer requires storing transaction data outside the original blockchain network. This could be another blockchain or any data storage system chosen by developers. In this case, the data availability layer focuses on storing data, not execution.
Data Availability Layers of Ethereum.
Sharding, an approach to blockchain scaling that involves splitting up a network into several sub-chains operating in parallel, is part of Ethereum’s current scaling roadmap. With sharding, Ethereum will employ multiple data availability layers instead of storing state data in one location. This directly translates to scalability because the network will be able to process transactions faster.
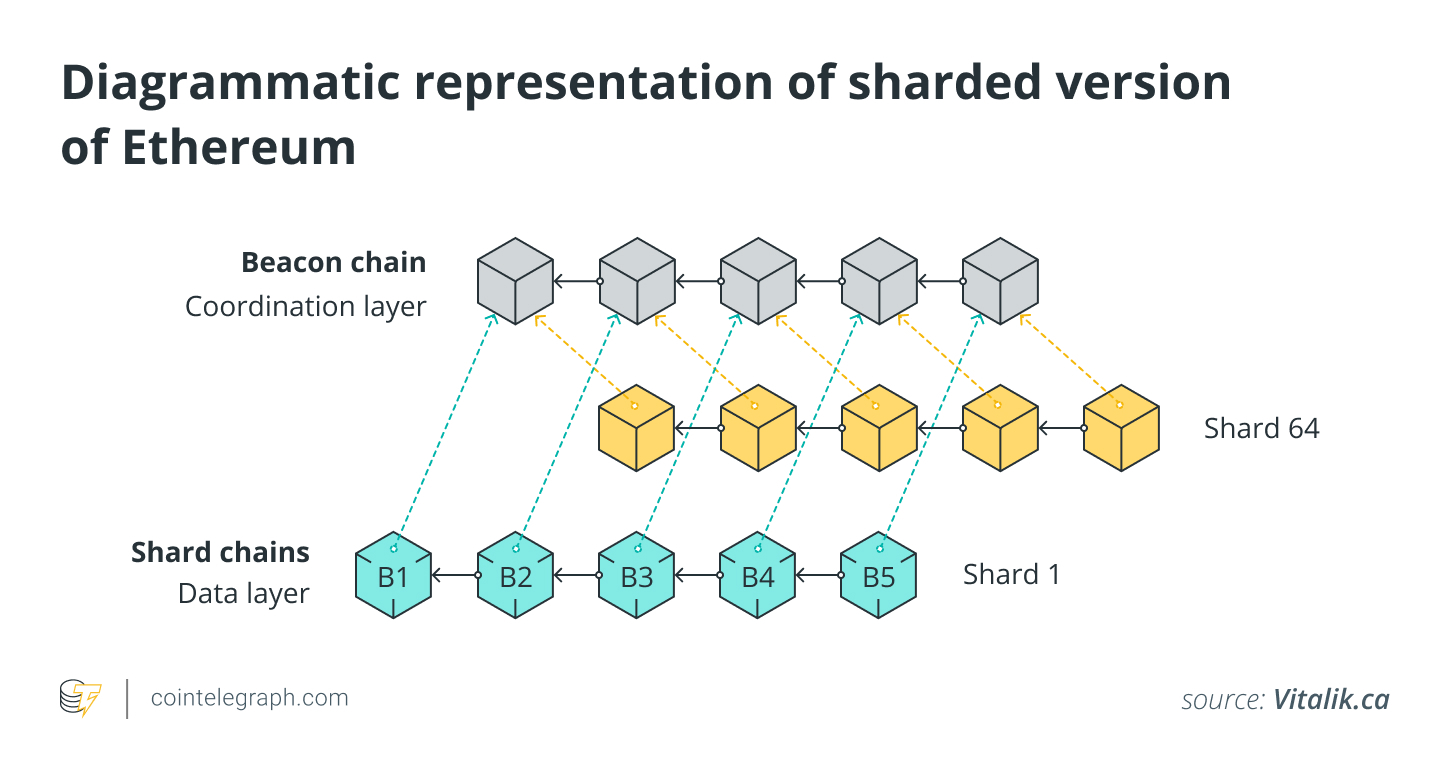
Data availability layers also could work with rollups, which scale Ethereum by moving computation and state storage away from Ethereum’s execution environment. Rollups rely on Ethereum for data availability, publishing transaction results and data on Layer 1 as CALLDATA. This promotes censorship resistance and allows anyone to execute transactions and validate the rollup chain.
A data availability layer itself is a modular chain since it concentrates on storing data and outsources execution to other chains. Unlike regular blockchains, a pure data availability layer will not check the validity of data published by block producers. Nodes only have to come to consensus on the ordering of transactions and confirm that the right fees were paid.

But as Execution Layer could be delegated to Layer 2 solutions, Data Availability could also be moved to a separate layer. Below we will explain the most promising projects and concepts.
Proto-Danksharding: Experimental Ethereum approach
Proto-Danksharding is an experimental solution that is part of the roadmap to full Ethereum blockchain sharding. It introduces a unique combination of cryptographic techniques and consensus algorithms to enhance data availability in Web3.
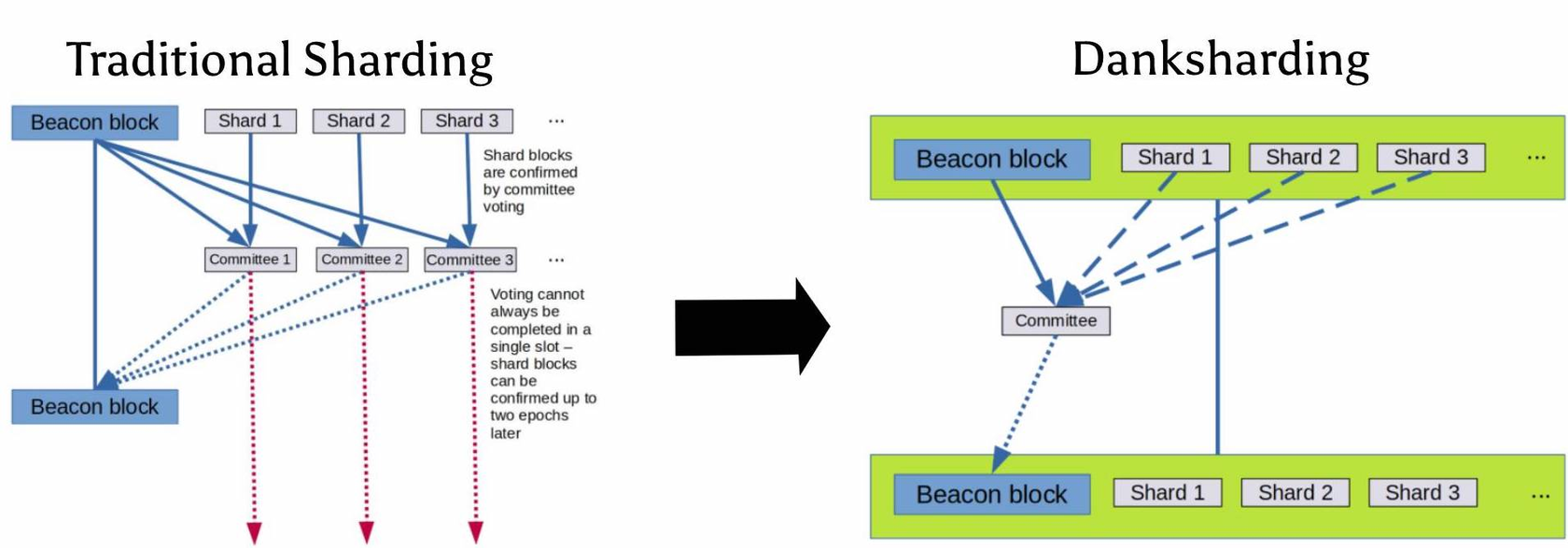
Sharding refers to splitting a blockchain into smaller portions to enhance overall efficiency. Proto-Danksharding takes this concept further by introducing the concept of Binary Large Objects, often called “blobs” for short. Blobs are proposed by block proposers and they are likened to big wraps or large portable bundles that can contain cheaper data. Each block can hold a limited size of these big wraps. In terms of structure, a typical blob has a body and a header. The body of a blob always stores the relevant pieces of data that relate directly to transactions. A header, on the other hand, contains lesser pieces of information, such as the signature of the proposer. In proto-danksharding, each transaction always has a blob twin, and the end goal of this is to make transactions cheaper.
One of the key features of Proto-Danksharding is data availability sampling. This is implemented with erasure codes, which can be sampled to get the actual data that was added to the slot or block. This ensures that the underlying data behind a particular hash has been published on-chain, enhancing the transparency and security of the network.
Proto-Danksharding also introduces a new set of actors in the Ethereum ecosystem: block builders and proposers. Block builders carry out the role of block construction, while block proposers select transaction headers that should be added to the block and broadcast them accordingly. These two work hand-in-hand to enhance the efficiency and scalability of the network.
While Proto-Danksharding is still in the experimental stage, it holds significant potential for enhancing the scalability of Layer 2 protocols and reducing transaction costs. As the Ethereum community continues to explore this new frontier, Proto-Danksharding could play a pivotal role in the future development and adoption of Web3 technologies. Let’s discuss the independent Data Availability projects.
Syntropy: Data Layer for Web3
Website: https://www.fuel.network/
Founded: 2017
Raised: > $10.5m
Status: N/A (probably closed Testnet)
Syntropy is a project that has recently shifted its strategic focus towards on-chain data and data availability. This decision was guided by a thorough strategic evaluation and the recognition of a rapidly expanding blockchain data sector. Syntropy aims to become an essential foundation for how decentralized applications (dApps) and protocols interact with blockchains.
Syntropy is developing a protocol that functions intrinsically within blockchain structures, replacing reliance on RPC nodes and APIs, and introducing a decentralized method of interacting with the blockchain. This transition positions Syntropy at the forefront of addressing Web3's complexities, enhancing blockchain scalability, and upholding the principles of decentralization, scalability, and security.
The Syntropy Data Availability Layer represents the best application of their routing protocol. They are pioneering an incentive layer that motivates blockchain nodes to stream current and historical data while participating in data availability attestation solutions. This constitutes a significant shift towards decentralization, where blockchain data becomes readily accessible for any application or derivative product reliant on data availability.
Key points of project:
- Real-time on-chain data streams: Syntropy is developing an open-source protocol that democratizes access to real-time blockchain data through real-time data streams. This empowers event-driven architectures, thereby enhancing the quality of future applications and decentralized services in the blockchain sphere.
- Historical on-chain data streaming: Syntropy aims to offer a streaming database for historical data, facilitating efficient access to past information and its seamless integration with real-time data streams under a unified schema.
- Data Availability Layer: Syntropy seeks to forge a comprehensive data availability layer where nodes can disseminate both transactional and availability-proof data, substantially bolstering blockchain throughput.
Celestia: Pioneering the Modular Blockchain Network
Website: https://celestia.org/
Founded: 2019
Raised: > $55.5m
Status: Incentivized Testnet

Celestia is a groundbreaking project that is redefining the landscape of blockchain technology. It is a modular consensus and data network, designed to empower anyone to deploy their own blockchain with minimal overhead. By decoupling the consensus and application execution layers, Celestia is modularizing the blockchain technology stack, unlocking new possibilities for decentralized application builders.
Key points of project:
- it separates the consensus and application execution layers, modularizing the blockchain technology stack.
- It operates as a minimal blockchain that only orders and publishes transactions, leaving their execution to developers.
- Developers can define their own virtual execution environments, with each application having its sovereign execution space.
- Application updates can occur without main chain hard forks, improving over traditional monolithic architecture.
- Its use of data availability sampling allows the network to scale dynamically with user increase.
- It introduces the concept of sovereign rollups, empowering developers to deploy their own blockchain in minutes.
Fuel: The Fastest Modular Execution Layer
Website: https://www.fuel.network/
Founded: 2019
Raised: > $81.5m
Status: Testnet
Fuel project focuses on building the fastest execution layer for modular blockchains. The future of blockchains is moving away from a monolithic design, where consensus, data availability, and execution are tightly coupled. Instead, the future is modular, where execution is separated from data availability and consensus, as seen in projects like Eth2 and Celestia. This separation allows for specialization at the base layer, delivering a significant increase in bandwidth capacity. Fuel aims to capitalize on this trend by building the fastest execution layer for the modular blockchain stack.
Key points of project:
- Parallel transaction execution: Fuel can execute transactions in parallel using strict state access lists as a UTXO model. This allows Fuel to use more threads and cores of your CPU that are typically idle in single-threaded blockchains, delivering far more compute, state accesses, and transactional throughput than its single-threaded counterparts.
- Fuel Virtual Machine (FuelVM): Designed to reduce wasteful processing of traditional blockchain virtual machine architectures while vastly increasing the potential design space for developers. The design learns from the mistakes of the past and insights from years of production blockchains.
- Sway Language: Fuel provides a powerful and sleek developer experience with its own domain-specific language, called Sway, and a supportive toolchain, called Forc. This development environment retains the benefits of smart contract languages like Solidity while adopting the paradigms introduced in the Rust tooling ecosystem.
Fuel's approach to modular execution allows it to better capitalize on high shared data availability, making it a unique solution among both layer-1 and layer-2 blockchains. This makes Fuel an important player in the field of data availability solutions in Web3.
EigenDA: Harnessing Zero-Knowledge Proofs for Hyperscale Data Availability
Website: https://www.eigenlayer.xyz/
Founded: 2021
Raised: $64.4m
Status: Testnet launch
EigenLayer provides developers access to the Ethereum staked capital basis and decentralized validator set. EigenDA, nestled within the EigenLayer ecosystem, is pioneering using zero-knowledge proofs (ZKPs) for data availability.
Key points of the project:
- It utilizes the power of zero-knowledge proofs (ZKPs) to ensure data availability and correctness without revealing the actual data
- Its unique approach combines ZKPs with decentralized storage networks, which distribute data across multiple nodes for enhanced security and ready availability.
Conclusion
Data availability solutions are crucial in enhancing blockchain capacity and reducing Layer 2 rollup costs. Projects like Celestia, EigenDA, Fuel, and Syntropy and approaches like Proto-Danksharding are offering innovative solutions that leverage advanced cryptographic techniques and consensus algorithms. As we move towards a future where Web3 technologies become increasingly prevalent, the importance of data availability solutions cannot be overstated. By ensuring that data is readily accessible, these solutions not only enhance the capacity of blockchain networks but also reduce transaction costs, making them more efficient and cost-effective. As such, they will play a pivotal role in the future development and adoption of Web3 technologies.
Check out our website and please join our community!